Spring 2026 Update
It’s been a busy start to the year. Since January, I’ve been heads-down building out features that I’ve wanted for a long time - and a few that surprised me along the way. Here’s what’s new.
Your Collection, Your Way
The biggest addition this spring is the new Collection & Wishlist system. This has been the most requested feature since FMDB launched, and I’m happy to say it’s finally here.You can now track which soundtracks you own, which ones you’re eyeing, and browse your collection the way you’d browse a record shelf. Every release page has 2 buttons that lets you add it to your collection or wishlist with a single click - no more navigating away to a separate page.Here’s what’s included:A dedicated Collection page where you can browse, filter, and search everything you’ve added. Grid view with covers, faceted search by format, label, year - it works the way you’d expect.Privacy controls. A three-tier visibility system (private, friends, public) lets you decide who sees your collection. This is a global setting - simple and predictable.Collection statistics that give you a quick overview: how many releases, which formats, which labels appear most. Nothing fancy, but it’s satisfying to see the numbers.Quick-add buttons across the site. When you’re browsing search results or an artist page, you can add releases to your collection without ever opening the detail page.The collection system is available to all registered users.See all features: https://www.fmdb.net/features/collection-managementAn API Is Taking Shape
Behind the scenes, I’ve been building out a proper REST API. It’s not publicly available yet - right now it powers the upcoming iOS app and some internal tooling - but it’s growing fast.The API covers releases, artists, labels, productions, recordings, collections, wishlists, and more. It uses JWT authentication, follows OpenAPI conventions, and returns properly structured data including cover images in multiple sizes via imgproxy.Some of the more specialized endpoints include audio feature submission (timbre, harmony, texture vectors per track), audio fingerprints, IFPI label codes, and disc scan data. These are building blocks for features that will become visible to users over time.When the API reaches a stable state, I plan to open it up - first as a beta for interested developers, eventually as a core part of the platform.Finding Things Faster
Two additions that have changed how I use FMDB myself:Quick Search (⌘K). Press Cmd+K (or Ctrl+K) anywhere on the site and a command palette opens. It searches across releases, artists, labels, and productions simultaneously via Meilisearch’s multi-index search. Results appear as you type. I use this dozens of times a day now - it’s the fastest way to navigate the database.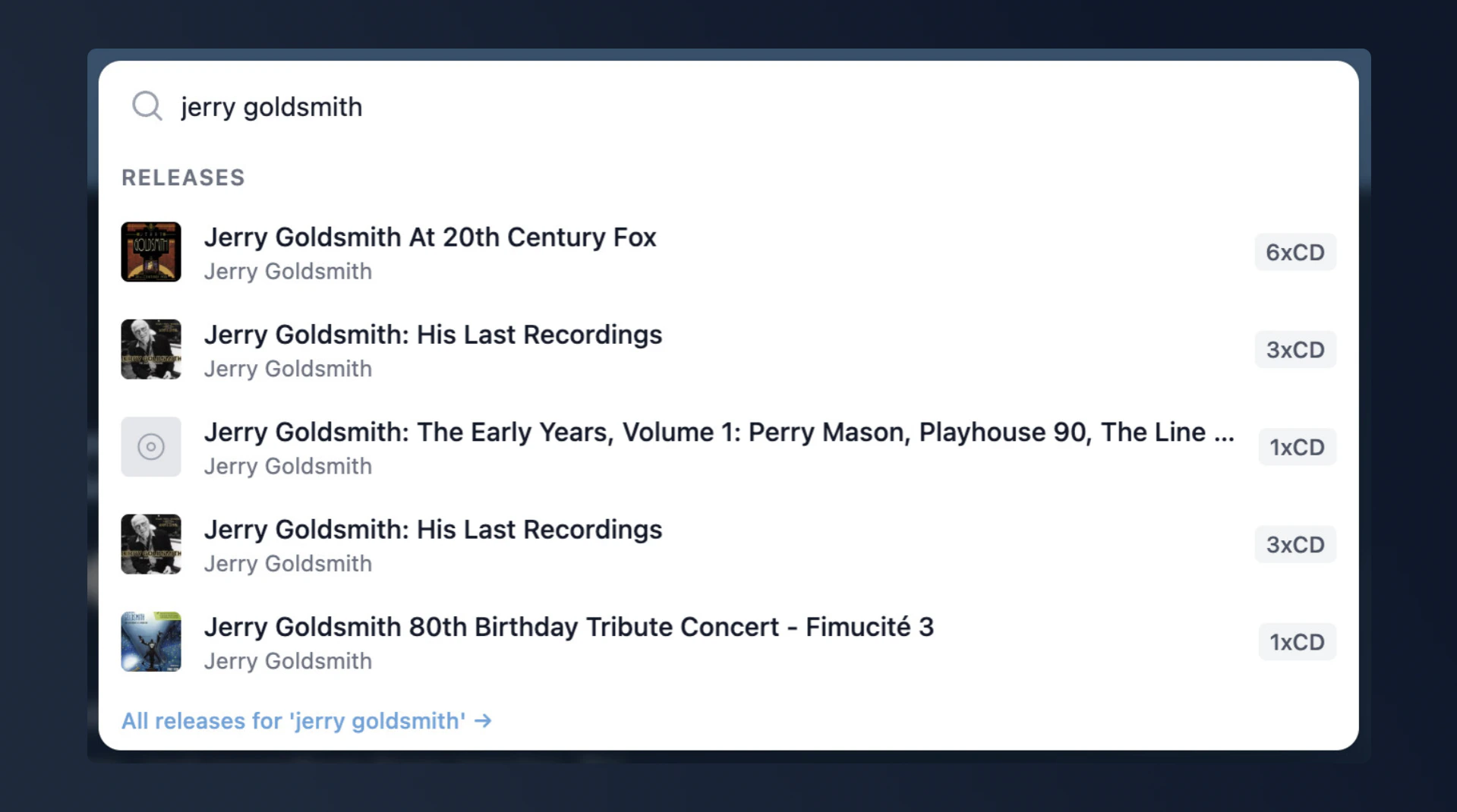
Source Cues on Tracks
A small but meaningful addition for film music nerds: tracks can now be marked as source cues. These appear as amber “Source” badges in the tracklist view.If you’re not familiar with the term - a source cue is music that exists within the world of the film. A song playing on a radio, a band performing at a party. It’s distinct from the underscore, which is the “invisible” music the audience hears but the characters don’t. Being able to distinguish the two in a tracklist gives you a much better picture of how a score is structured.External Links: MusicBrainz & VGMdb
Releases, artists and labels can now be linked to their MusicBrainz and VGMdb pages. These links appear on detail pages and help connect FMDB’s data with two of the most important external databases in the music and soundtrack space.MusicBrainz is the open music encyclopedia - it’s especially strong on metadata standards and identifiers. VGMdb is the reference for video game and anime music, an area where FMDB is growing but VGMdb has decades of depth.Apple Music badges appear on production pages where applicable.Schema.org: Better Visibility in Search Engines
This one isn’t visible in the UI, but it matters for discoverability. Release pages now include Schema.org structured data in JSON-LD format.Every release page outputs aMusicAlbum schema with track listings, artist credits, label info, and ISRC codes where available. Artist pages output MusicGroup schemas. The site also supports BreadcrumbList navigation and a SearchAction so Google can offer direct searches into FMDB.The result: FMDB pages are now eligible for rich results in Google Search - album cards with track listings, artist knowledge panels, and direct search integration.Platform Statistics
There’s a new Statistics page that shows a high-level overview of the database: how many releases, artists, labels, and productions are catalogued. It’s a simple snapshot, but it’s the first time this data has been surfaced publicly.Behind the Scenes: The Release Backlog
This section is a bit different - it’s about a system that most users won’t interact with directly, but that shapes everything they see in the database.The Release Backlog is where new releases enter FMDB before they become full database entries. When I discover a new soundtrack release - from a press announcement, a label catalog, a forum post - it goes into the backlog as a raw text line. Something like: